s03: Distributions
Contents
s03: Distributions#
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
Probability Distributions#
Typically, given a data source, we want to think about and check what kind of probability distribution our data sample appears to follow. More specifically, we are trying to infer the probability distribution that the data generator follows, asking the question: what function could it be replaced by?
Checking the distribution of data is important, as we typically want to apply statistical tests to our data, and many statistical tests come with underlying assumptions about the distributions of the data they are applied to. Ensuring we apply appropriate statistical methodology requires thinking about and checking the distribution of our data.
Informally, we can start by visualizing our data, and seeing what ‘shape’ it takes, and which distribution it appears to follow. More formally, we can statistically test whether a sample of data follows a particular distribution.
Here we will start be visualizing some of the most common distributions. Scipy (scipy.stats) has code for working with, and generating different distributions. We will generate synthetic data from different underlying distributions, and do a quick survey of how they look, plotting histograms of the generated data.
You can use this notebook to explore different parameters to get a feel for these distributions. For further exploration, explore plotting the probability density functions of each distribution.
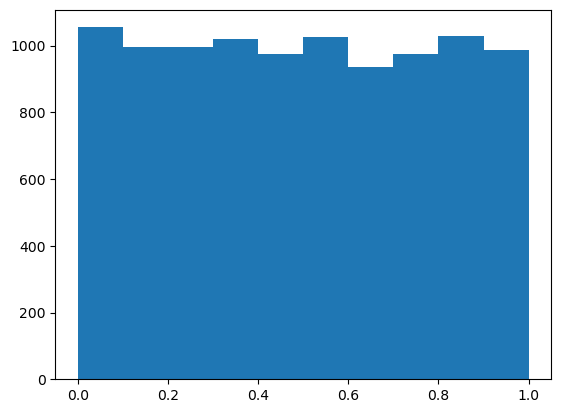
Uniform Distribution#
from scipy.stats import uniform
data = uniform.rvs(size=10000)
plt.hist(data)
(array([1055., 996., 997., 1020., 974., 1027., 937., 976., 1030.,
988.]),
array([6.36883846e-05, 1.00057017e-01, 2.00050346e-01, 3.00043675e-01,
4.00037004e-01, 5.00030333e-01, 6.00023662e-01, 7.00016991e-01,
8.00010320e-01, 9.00003649e-01, 9.99996978e-01]),
<BarContainer object of 10 artists>)
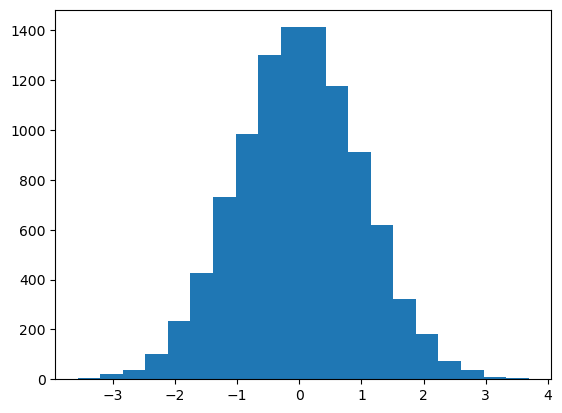
Normal Distribution#
from scipy.stats import norm
data = norm.rvs(size=10000)
plt.hist(data, bins=20)
(array([ 7., 20., 39., 103., 234., 426., 731., 982., 1301.,
1412., 1412., 1175., 910., 618., 324., 180., 73., 36.,
10., 7.]),
array([-3.56114559, -3.19865574, -2.83616588, -2.47367602, -2.11118616,
-1.7486963 , -1.38620645, -1.02371659, -0.66122673, -0.29873687,
0.06375299, 0.42624284, 0.7887327 , 1.15122256, 1.51371242,
1.87620228, 2.23869213, 2.60118199, 2.96367185, 3.32616171,
3.68865156]),
<BarContainer object of 20 artists>)
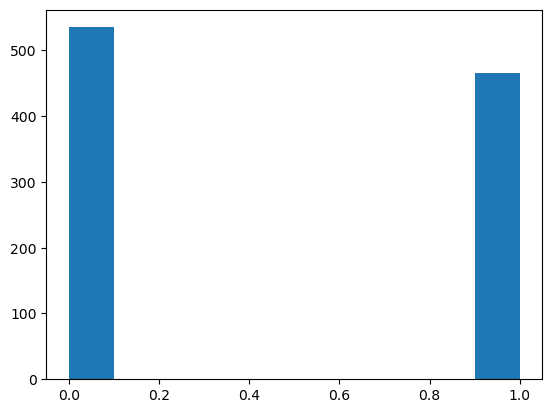
Bernouilli Distribution#
from scipy.stats import bernoulli
data = bernoulli.rvs(0.5, size=1000)
plt.hist(data)
(array([535., 0., 0., 0., 0., 0., 0., 0., 0., 465.]),
array([0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1. ]),
<BarContainer object of 10 artists>)
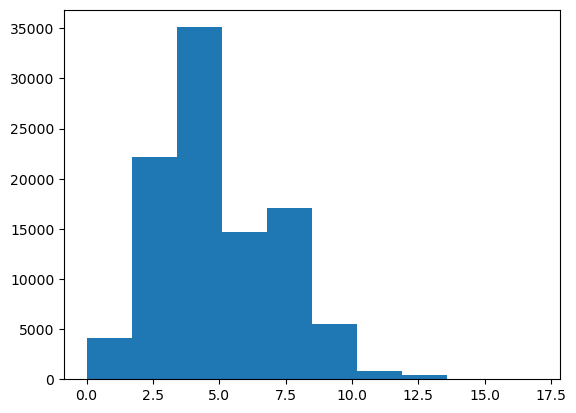
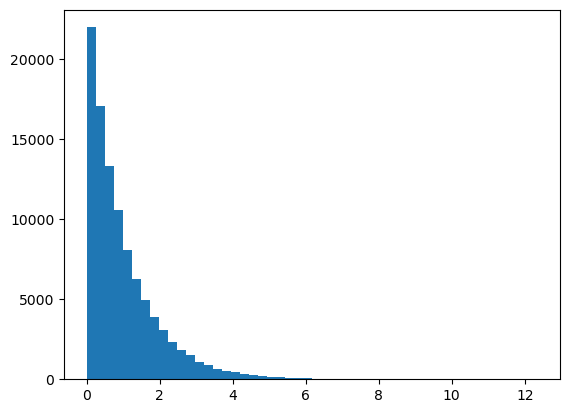
Gamma Distribution#
Given different parameters, gamma distributions can look quite different. Explore different parameters.
The exponential distribution is technically a special case of the Gamma Distribution, but is also implemented separately in scipy as ‘expon’.
from scipy.stats import gamma
data = gamma.rvs(a=1, size=100000)
plt.hist(data, 50);
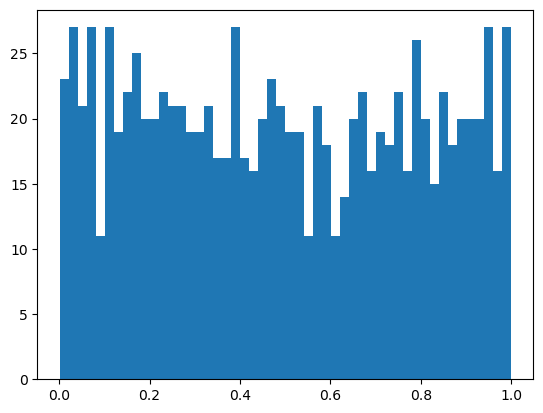
Beta Distribution#
from scipy.stats import beta
data = beta.rvs(1,1, size=1000)
plt.hist(data, 50);
Poisson Distribution#
from scipy.stats import poisson
data = poisson.rvs(mu=5, size=100000)
plt.hist(data);